借助NVIDIA Aerial CUDA加速RAN,提升5G/6G DU性能和工作负载整合

Aerial CUDA 加速无线接入网 (RAN)可加速电信工作负载,使用 CPU、GPU 和 DPU 在云原生加速计算平台上提供更高水平的频谱效率 (SE)。
适用于 Aerial 的 NVIDIA MGX 系统基于先进的 NVIDIA Grace Hopper 超级芯片和 NVIDIA Bluefield-3 DPU 构建,旨在加速 5G 端到端无线网络:
这种全栈加速方法可提供领先的性能和频谱效率,同时降低总拥有成本(TCO),并为更好的资产回报(ROA)开辟新的盈利机会。NVIDIA 6G 研究云平台中提供了 Aerial CUDA 加速的 RAN 软件堆栈。
电信公司已投入数十亿资金购买 4G/5G 频谱,预计他们将再次投入购买 6G 频谱,以满足日益增长的移动用户需求。
该生态系统包括芯片制造商、OEM 和独立软件供应商(ISV),可提供具有不同性能特征的解决方案。这些解决方案主要基于专用硬件,例如专用集成电路(ASIC)或系统级芯片(SoC),用于处理计算密集型第 1 层(L1)和第 2 层(L2)功能。
挑战在于如何在 RAN 解决方案中实施算法的复杂程度与实施成本和功耗之间取得平衡。
电信公司希望能够分解 RAN 工作负载的硬件和软件,使其能够在云基础设施上构建网络,从而为软件创新、新的差异化服务、控制硬件生命周期管理以及提高总体拥有成本(TCO)开辟可能性。
vRAN 展示了商用现成(COTS)平台运行 RAN 分布式单元(DU)工作负载的能力。但是,由于计算性能差距,需要加速,从而实现某些工作负载的固定功能加速,例如前向纠错(FEC)。
在本文中,我们将讨论用于 DU 工作负载加速的 Aerial CUDA 加速 RAN 的进展,详细介绍所使用的算法和预期收益、所使用的底层硬件,以及它整合 DU、集中式单元(CU)和核心等电信工作负载以及使用多租户功能托管创收工作负载的能力。最后,我们将探讨电信公司有望实现的总体 TCO 和 ROA 优势。
Aerial CUDA 加速 RAN
NVIDIA Aerial RAN 将适用于 5G 和 AI 框架的 Aerial 软件与 NVIDIA 加速计算平台相结合,帮助电信公司降低 TCO 并实现基础设施盈利。
Aerial RAN 具有以下主要特性:
全栈加速
全栈加速依托如下两个支柱:
图 1 显示加速 DU L1 和 L2 是 NVIDIA 实现全栈加速的关键方面。
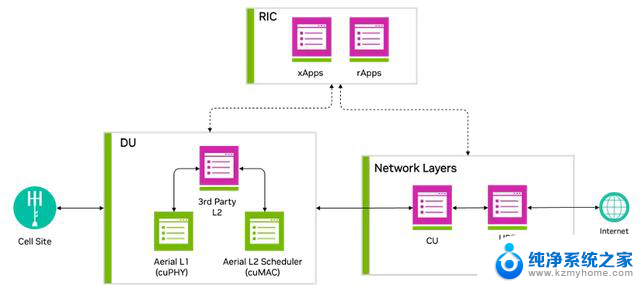
图 1. Aerial RAN 堆栈
DU 加速
Aerial 已实施先进算法,以提高 RAN 协议栈的频谱效率,涵盖 DU L1 和 L2。
本文中介绍的加速 L1 和 L2 功能是通过一种利用加速计算平台内的 GPU 并行计算能力的通用方法实现的。
图 2 显示 MGX 服务器平台在同一 GPU 实例上托管经加速的 L1 cuPHY 和 L2 MAC 调度程序 cuMAC,并由 CPU 托管 L2+ 堆栈。这展示了基于 GPU 的平台在同时加速多个计算密集型工作负载方面的强大功能。
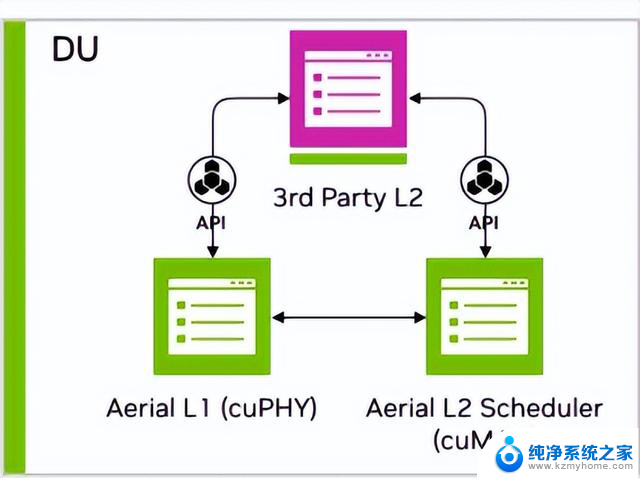
图 2. cuPHY 和 cuMAC 软件架构
L1 (cuPHY)
Aerial cuPHY 是 RAN 物理层 L1 的数据和控制通道的 3GPP 兼容、GPU 加速的全内联实现。它提供 L1 高 PHY 库,通过利用 GPU 的强大计算能力和高度并行性来处理 L1 的计算密集型部分,提供无与伦比的可扩展性。它支持标准多输入多输出(sMIMO)和大规模 MIMO(mMIMO)配置。
作为一种软件实现,它支持持续增强和优化工作负载,正如 cuPHY 随着时间推移在 AX800 加速平台和全新 MGX 平台上持续实现容量提升。
L1 中的信道估计是任何无线接收机中的基础块,优化的信道估计器可以显著提高性能。传统的信道估计方法包括最小平方(LS)或最小均方误差(MMSE)。这些方法的比较总结在表 1 中。

表 1. 不同信道估计方法的比较
NVIDIA 使用新的通道估计器增强了 cuPHY L1,该估计器的性能优于表 1 中列出的方法。此实现使用复制核 Hilbert 空间(RKHS)通道估计器算法。
RKHS L1 信道估计
RKHS 信道估计专注于时域信道脉冲响应(CIR)的有意义部分,可限制不必要的噪声并放大脉冲响应的相关部分(图 3)。
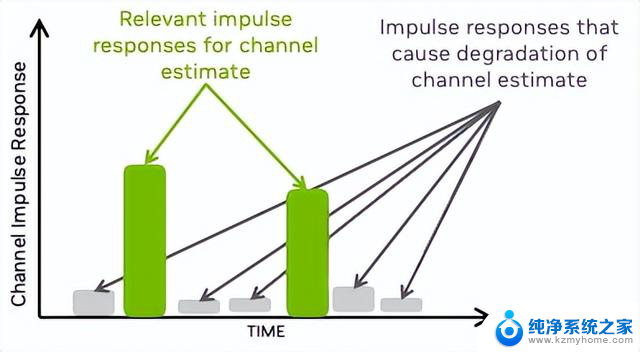
图 3. RKHS 信道估计方法
RKHS 需要复杂的计算,接近无限凸优化问题。RKHS 将这个无限凸问题转换为有限凸问题,而不会损失任何性能。
RKHS 计算密集型,非常适合在 GPU 上进行并行处理。表 2 总结了 sMIMO 和 mMIMO 配置的 RKHS 增益和计算需求。

表 2. RKHS 信道估计优势和实现需求汇总
RKHS 计算得出的 CIR(图 4)与实际通道(在模拟环境中测量得出)非常接近,用于具有四个天线和两个 UL 层的分接延迟线(TDL)- C 通道模型。
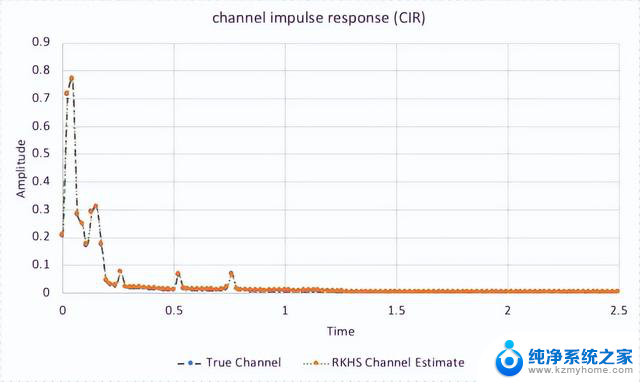
图 4. RKHS 信道估计改进
在一系列调制和编码方案(MCS)中,与信噪比(SNR)曲线相比,改进后的 CIR 显著提高了误码率(BER)。图 5 显示了 RKHS 相对于 MMSE(具有两个不同的窗口,1 s 和 2.3 s)的优势,对于 MCS 15,可提供高达 2.5 dB 的增益。
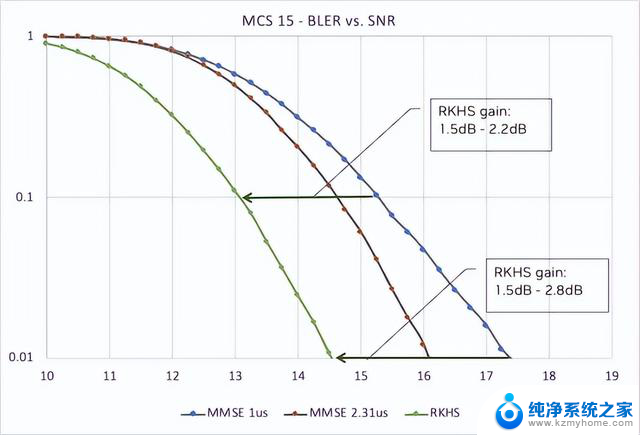
图 5. RKHS 信道估计 dB 增益
L2 (cuMAC)
RAN 协议栈中的 L2 MAC 调度程序在决定 UE 如何访问无线电资源方面发挥着重要作用。而这反过来又决定了整个网络的频谱效率。
对于 5G 系统,有许多自由度,包括:
典型的调度程序专注于单个单元,这会限制实现的性能。表 3 显示了典型调度程序方法的比较。

表 3. 典型调度程序方法对比
在 NVIDIA ,我们使用比例公平(PF)算法实施了多单元调度程序,其性能优于表 3 中列出的两种方法。
多单元调度程序
NVIDIA 多单元调度程序通过优化大量相邻单元的调度参数(TTI、PRB、MCS 和 MIMO 层),显著提高了无线性能(图 6)。
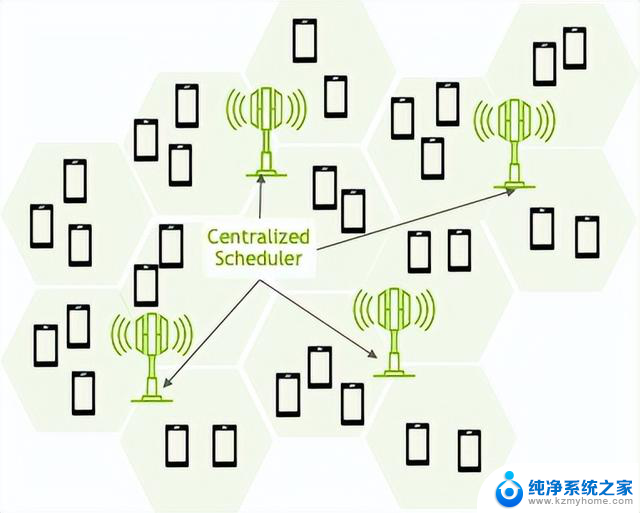
图 6. 多单元调度器方法
使用 PF 算法的多单元调度需要复杂的计算逻辑来解决所有单元中的各种变量。这非常适合具有大规模并行处理能力的 GPU。表 4 总结了 sMIMO 和 mMIMO(联合调度 20 个单元)的优势和计算需求。如您所见,CPU 计算需求很高。

表 4. 多单元调度程序优势和实施需求汇总
图 7 显示了 20 个 100MHz 4T4R 4DL/2UL 单元(每个单元具有 500 个活跃 UE 和 16 个 UE/TTI)的频谱效率。
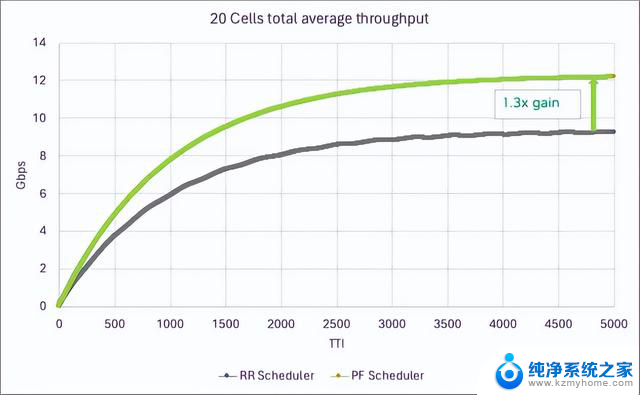
图 7. 多单元调度器增益
DU 综合加速提升
总而言之,RKHS 信道估计支持每个 UE 更高的 MCS 分配,而多单元调度器代表了无线电资源调度的重大飞跃。这两种方法都能显著提高频谱效率,并在 GPU 上得到优化实施。
例如,对于 6 单元的 100MHz 64T64R 系统,实现 2 倍以上的 SE 增益将需要大约 240 个核心(大约 8 个 32 核心 CPU),需要额外的 CPU 服务器。相较于 GPU 实现,其中 L1 PHY 处理和 L2 调度程序托管在单个服务器中的单个 GPU 上。
工作负载整合
如前文所述,全栈加速的第二个支柱是整合多个工作负载并在 Aerial RAN 上加速这些工作负载。这是通过利用 NVIDIA 加速计算平台中的 GPU、CPU 和 DPU 的可用计算资源来实现的。
针对电信工作负载,MGX 系统提供针对数据中心的模块化和可扩展架构。该系统可提供所需的计算能力,以整合 RAN CU、RAN 智能控制器(RIC)应用等功能以及 UPF 等核心功能。
NVIDIA Grace Hopper 超级芯片结合了 NVIDIA Grace 和 NVIDIA Hopper 架构,使用 NVIDIA NVLink-C2C 为 5G 和 AI 应用提供 CPU+GPU 一致性内存模型。
CU 可以利用许多 Grace CPU 核心。RIC 应用程序(例如通常包含 AI/ML 技术以提高频谱效率的 xApp)可以在 GPU 上进行加速。
随着我们进一步进入网络,UPF 等功能通过使用关键的 DPU 功能可以从 DPU 加速中受益:
工作负载整合使电信公司能够更大限度地减少部署在数据中心的服务器数量,从而全面提高 TCO。
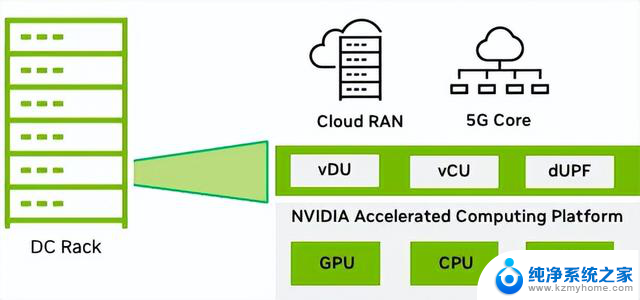
图 8. 支持工作负载整合的 NVIDIA MGX
多租户 Aerial RAN
电信公司需要一个可以满足电信工作负载严苛的性能和可靠性要求的平台,能够在一个通用平台上托管不同类型的电信工作负载(从 RAN 到核心)。
电信 RAN 基础设施的利用率明显不足。借助多租户云基础设施,电信公司可以在有闲置容量时通过可盈利的应用程序提高利用率。
可以为电信公司提供盈利机会的工作负载类型包括生成式 AI 和基于大语言模型(LLM)的多接入边缘计算(MEC)应用程序。这些类型的工作负载在分布式电信边缘数据中心引发了前所未有的计算需求。
由于需要在边缘支持大量基于 LLM 的应用程序,因此专用于执行 LLM 推理的边缘 GPU 服务器和各种 MEC 应用程序正在大幅增加。
图 9 显示了 MGX 平台,该平台可以托管所有工作负载,并帮助电信公司克服计算资源利用不足的问题,减少总体能源足迹,并提高基础设施的货币化程度。
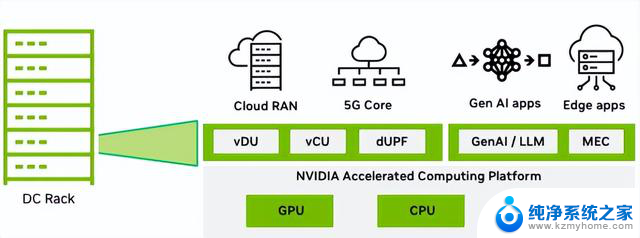
图 9. NVIDIA MGX 共享 AI 和电信基础设施
Aerial CUDA 加速 RAN 的优势
到目前为止,我们已经讨论了 NVIDIA Aerial 软件如何帮助提高整体频谱效率,以及加速计算平台如何提供处理能力,以在同一平台上整合多个工作负载。
多租户平台支持 AI 工作负载的货币化。5 年期 TCO 分析显示,该平台的可用时间约为 AI 的 30%,并考虑到典型的每小时 GPU 定价,可提供显著抵消平台成本的收入。与仅使用 CPU 的系统相比,此 ROA 对每美元指标的性能有重大影响。
根据条形图显示,与 x86 CPU 相比,采用 AI 创收的 GPU 的每成本性能提升了 4.1 倍。
结束语
总而言之,Aerial RAN 可提供出色的 TCO 并释放新的收入机会,从而更大限度地提高投资回报率(ROA)。
NVIDIA 正在改变电信基础设施,该基础设施基于 NVIDIA 加速计算平台构建,并由 Aerial 软件提供支持。Aerial CUDA 加速的 RAN 可满足电信公司的愿望,以 TCO 高效的方式提供市场领先的无线功能,并能够开始以当今部署的基础设施无法实现的方式从部署的基础设施中获利。
在本文中,我们详细介绍了使用新算法在 L1 和 L2 上实现的频谱效率提升,并讨论了基于 RAN 和 LLM 的工作负载加速 AI 工作负载的能力。新一代 NVIDIA 平台将通过提供更高的单元密度和更高的工作负载加速来进一步改进这些关键指标。
Aerial CUDA 加速 RAN 作为 NVIDIA 6G 研究云平台的一部分提供。有关访问的更多信息,请参阅 NVIDIA Aerial:
https://developer.nvidia.com/aerial